A Dialectic Pipeline for Improving LLM Robustness
Can LLMs improve their accuracy without further training, just through a dialectic way of questioning themselves — as Hegel suggested?
This was the core question behind my Master’s thesis. The short answer: yes, and by a lot.
The Idea
Inspired by Hegelian dialectics, the pipeline structures reasoning into three stages:
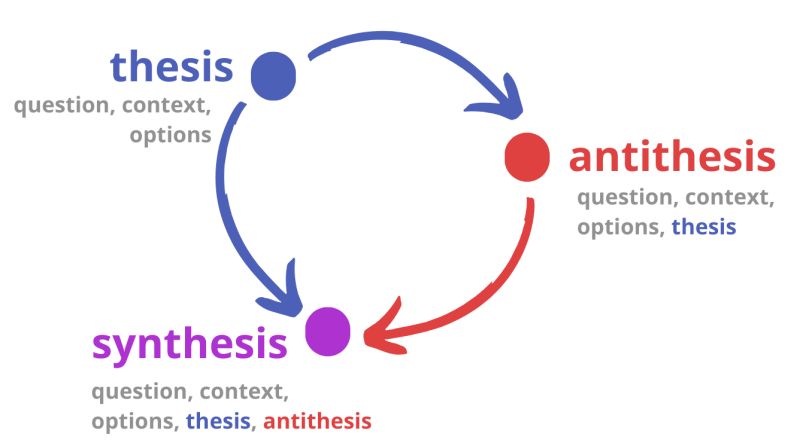
The thesis–antithesis–synthesis pipeline.
- Thesis — the model produces an initial answer given the question, context, and options.
- Antithesis — the model challenges its own answer, now also seeing the thesis.
- Synthesis — the model produces a final answer, having seen both thesis and antithesis.
No fine-tuning. No domain-specific verifiers. Just structured self-dialogue.
Results
The pipeline was tested on multi-hop QA benchmarks (HotpotQA, WikiHop) across five open-source models under 20B parameters (Phi-mini, Phi-medium, Gemma-2B, Gemma-9B, LLaMA-8B).

Accuracy improvements across models on HotpotQA.
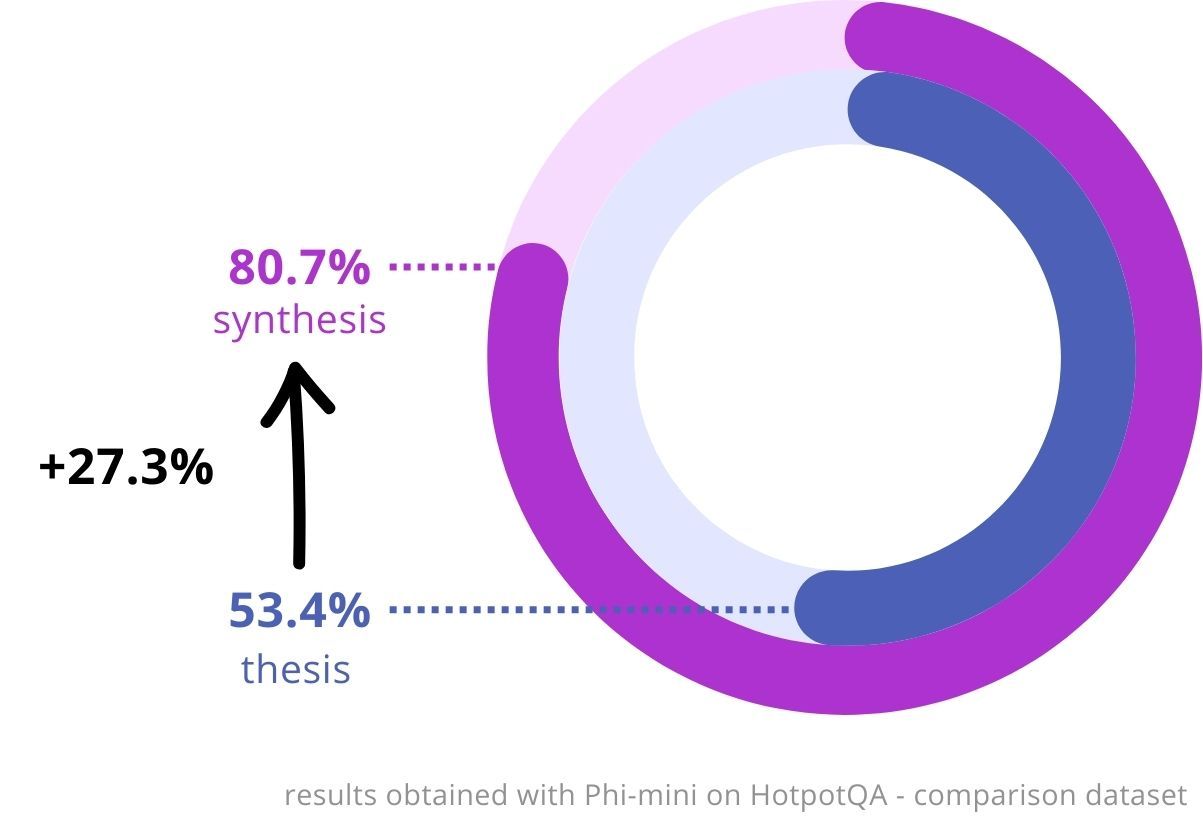
From 53.4% to 80.7% on HotpotQA with Phi-mini (+27.3%).
Improvements of up to 30% on complex multi-hop questions — beating standard Chain-of-Thought prompting.
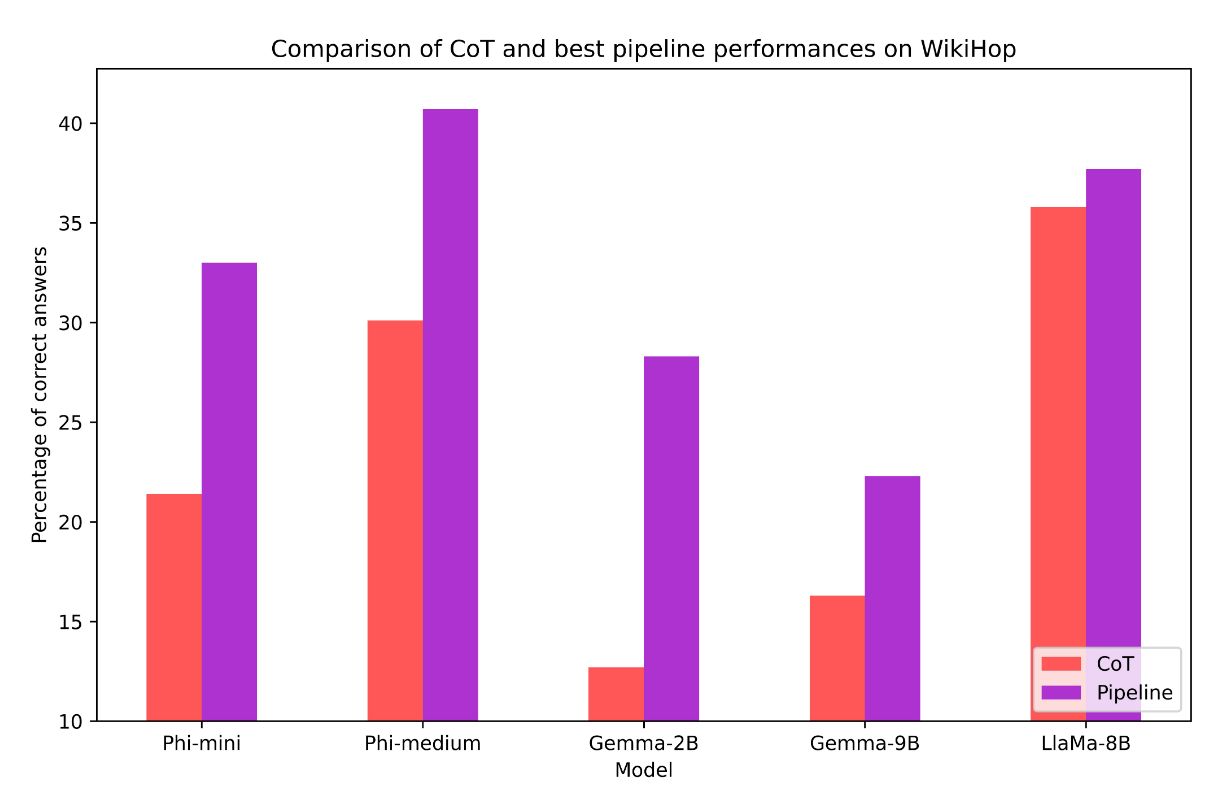
CoT vs. pipeline on WikiHop across all models.
Key Takeaways
- Self-debating is the main driver: letting models reflect on and contrast their own reasoning significantly boosts performance, especially as question complexity increases.
- Instruction following matters: models that strictly follow instructions (Llama, Phi) benefit more than those that get “too creative” (Gemma-2).
- Smart filtering > summarization: when dealing with long contexts, filtering for relevant information beats summarization, which can hurt deductive reasoning.
- Avoid overthinking: for simpler tasks, too much deliberation can introduce errors. A touch of “impulsivity” sometimes helps.
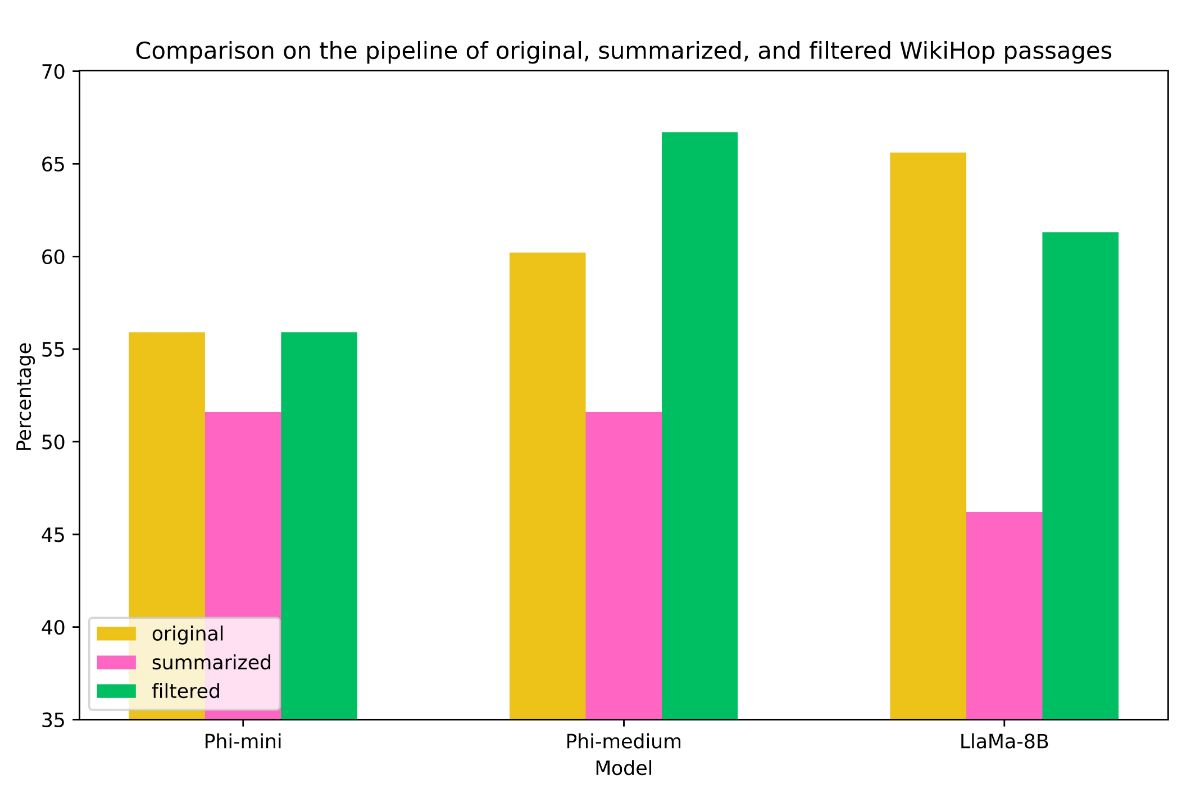
Original vs. summarized vs. filtered context on WikiHop.
This work also received an Honorable Mention at the Emanuele Pianta Award (AILC) for the best Italian NLP Master’s thesis at CLiC-it 2025. 🏆

CLiC-it 2025, Cagliari.
If you’re interested in agentic reasoning, small language models, or multi-hop QA — feel free to reach out!